API, 웹 스크래핑, 데이터베이스 등으로 수집한 데이터는 값이 잘못 들어가 있거나 불필요한 문자가 섞여 있을 수 있어 불완전하다. 또 분석에 필요하지 않은 행이나 열이 있다면 제거해야 한다. 판다스 데이터프레임의 다양한 기능을 사용해 불필요한 데이터를 삭제하는 방법을 알아보자.
열 삭제하기
gdown 패키지를 사용해 데이터를 다운로드 한다.
import gdown
gdown.download('https://bit.ly/3RhoNho', 'ns_202104.csv', quiet=False)
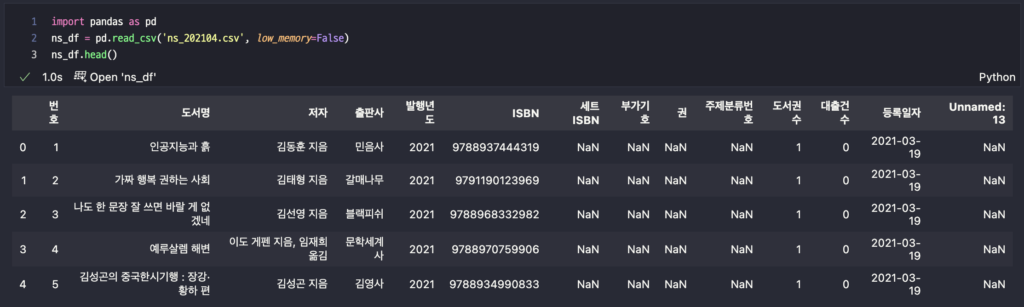
판다스 데이터프레임으로 읽어서 처음 다섯 개 행을 출력한다.
import pandas as pd
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()low_memory=False 옵션은 pandas의 read_csv 함수에서 사용되며, 데이터를 불러올 때 메모리 최적화와 관련된 설정이다. 기본 옵션은 True인데 False로 설정하면 pandas가 파일을 불러 올 때 열(column)의 데이터 타입을 추정하는 과정에서 다른 방식을 사용한다.
low_memory 옵션의 동작 방식
- low_memory=True (기본값)
- Pandas가 파일을 작은 조각으로 나누어 읽는다.
- 각 조각에서 데이터 타입을 추정하고, 전체 파일에 걸쳐 일관된 데이터 타입을 유지하기 위해 필요한 경우 타입을 변경한다.
- 이 방식은 메모리 사용량을 줄이지만, 데이터 타입 추정에서 일관성 문제가 발생할 수 있다. 특히, 큰 파일을 다룰 때 데이터의 일부가 다른 타입으로 잘못 인식될 수 있다.
- low_memory=False
- 전체 파일을 한 번에 읽어들여 열의 데이터 타입을 추정한다.
- 이 방식은 더 많은 메모리를 사용하지만, 데이터 타입 추정의 정확도가 높아진다.
- 큰 파일을 처리할 때 메모리 오버헤드가 발생할 수 있지만, 데이터 타입의 일관성을 유지하는 데에는 더 효과적이다.
그럼, 어떨 때 사용할까?
low_memory=False는 특히 큰 데이터셋을 처리할 때 유용할 수 있으며, 데이터 타입의 정확성이 중요한 경우에 적합하다. 그러나, 충분한 메모리 리소스가 필요.- 반면, 메모리 자원이 제한적인 환경에서는
low_memory=True설정이 더 적합할 수 있다.
loc 메서드 슬라이싱 사용
# NaN의 값을 가진 마지막 컬럼 삭제
ns_book = ns_df.loc[:, '번호':'등록일자']
ns_book.head()‘번호’ 열부터 ‘등록일자’ 열까지 전체 행을 선택해서 새로운 데이터 프레임을 만든다.
loc 메서드와 불리언 배열
하지만 만약 중간에 있는 ‘부가기호’ 열을 제외하고 선택하기에는 loc 메서드 슬라이싱으로는 어렵다.
이럴 때 불리언 배열(boolean array)을 사용한다.
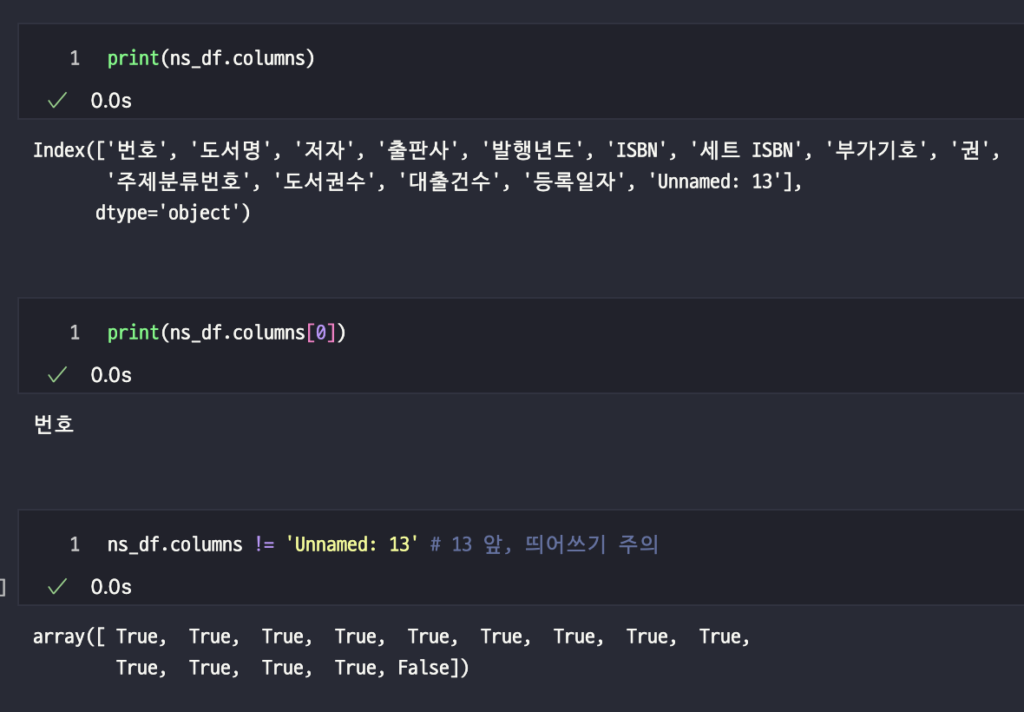
selected_columns = ns_df.columns != 'Unnamed: 13'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()정리하자면, 원소별 비교 연산으로 불리언 배열을 얻고, 이것을 selected_columns 변수에 저장, 판다스 데이터프레임의 loc 메서드에 전달하여 True인 열의 행만 선택할 수 있다. 여기서 결과는 위와 같다.
같은 코드에 ‘Unnamed: 13’대신에 ‘부가기호’열을 넣어주면 슬라이싱과 달리 중간에 있는 열을 제외할 수 있다.
selected_columns = ns_df.columns != '부가기호'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()dropna()메서드
판다스는 비어있는 값을 Nan으로 표시한다.
drop() 메서드와 비슷한 dropna()메서드는 기본적으로 Nan이 하나 이상 포함된 행이나 열을 삭제한다. ‘axis = 1’은 열을 의미한다.
ns_book = ns_df.dropna(axis=1)
ns_book.head()
모든 값이 Nan인 열을 삭제하려면 dropna() 메서드에 (how=’all’)로 지정한다.
ns_book = ns_df.dropna(axis=1, how='all')
ns_book.head()이때 dropna() 메서드도 inplace=True를 지정하여 데이터프레임을 새로 생성해서 반환하지 않고 현재 데이터프레임을 수정할 수 있다.
✔️ 정리
- loc 메서드로 필요한 열을 선택하려면; 슬라이스 연산자 또는 불리언 배열을 사용
- drop()메서드로 열을 삭제하려면; axis=1 또는 삭제하려는 열을 지정
- 삭제할 열이 여러 개일 때는 열 이름을 리스트로 전달 할 수 있음
- 또는 dropna() 메서드에 axis=1을 지정하면 NaN이 들어 있는 열을 삭제 할 수 있음
행 삭제하기
drop()메서드에서 ‘axis=0’ 으로 지정하여 행을 삭제한다.
기본값이 0이기 때문에 생략해도 괜찮다.
ns_books2 = ns_book.drop([0,1])
ns_book2.head()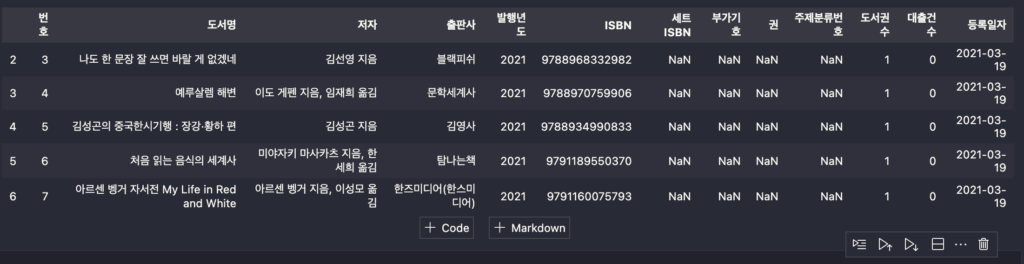
실행 결과 인덱스 0과 1에 해당하는 행이 삭제된 것을 볼 수 있다.
[] 연산자와 슬라이싱
위에 인덱스를 직접 지정해서 행을 삭제하는 것보다 더 자주 사용하는 [ ]연산자가 있다.
ns_book2 = ns_book[2:]
ns_book2.head()인덱스 0, 1인 행을 제외한 모든 행을 선택하기 위와 같은 슬라이싱을 사용했다.
✔️ 정리
- loc 메서드에 슬라이싱을 사용하면 마지막 인덱스를 포함하지만,
- [ ] 연산자에 슬라이싱을 사용하면 마지막 인덱스를 포함하지 않음.
[] 연산자와 불리언 배열
중복된 행 찾기
그룹별로 모으기
원본 데이터 업데이트하기
원본 데이터프레임 인덱스 설정하기
업데이트하기:update()메서드
일괄 처리 함수 만들기
일괄 처리 함수
🍒 확인문제

답글 남기기