공개 API에서 데이터를 수집하는 과정은 비교적 자동화하기 쉽다. 하지만 이런 데이터 소스를 사용할 수 없고 원하는 데이터가 인터넷 웹 페이지에 있다면 직접 HTML의 내용을 읽어 원하는 정보를 뽑아내야 한다. 이 방식은 최후의 수단이지만 이따금 필요할 때가 자주 있다.
도서 쪽수를 찾아서
온라인 서점은 도서에 관한 정보를 제공하는데, 도서 쪽수도 있다. 하지만 온라인 서점이 이런 정보를 API로 제공하지는 않는다.
예로 Yes24 사이트의 URl의 파라미터를 보면 끝단 쪽에 숫자로만 이루어져있는데 이것은 사이트에서 자체적으로 관리하는 제품 번호이다. (http://www.yes24.com/Product/Goods/96024871)
이 숫자를 ISBN이라고 한다. 따라서 http://www.yes24.com/Product/Search?domain=BOOK&query=9791162243664 이 URL을 활용해서 뒷단 query= 에 ISBN을 넣으면 쉽게 원하는 도서가 들어 있는 결과 페이지를 얻을 수 있다.
이 검색 결과 페이지 HTML에서 상세 페이지로 연결되는 링크 URL을 찾아야 한다.
requests 패키지를 사용하면 검색 결과 페이지의 HTML을 비교적 쉽게 얻을 수 있지만, 문제는 그 다음이다. HTML에서 도서 상세 페이지로 넘어가는 링크 URL을 찾아야 하는데 이건 쉬워 보이지 않는다.
도서관 정보나루에서 얻은 도서 목록에는 ISBN이 있으므로 Yes24 검색 결과 페이지의 URL을 바로 만들 수 있다. 하지만 여전히 상세 페이지로 넘어가는 링크를 어떻게 가져올지 생각해 봐야 한다.
검색 결과 페이지 가져오기
코랩에서 gdown 패키지를 사용해 미리 구글 드라이브에 올려 놓은 도서 목록을 불러오자.
import gdown
gdown.download('https://bit.ly/3q9SZix', '20s_best_book.json', quiet=False)import pandas as pd
books_df = pd.read_json('20s_best_book.json')
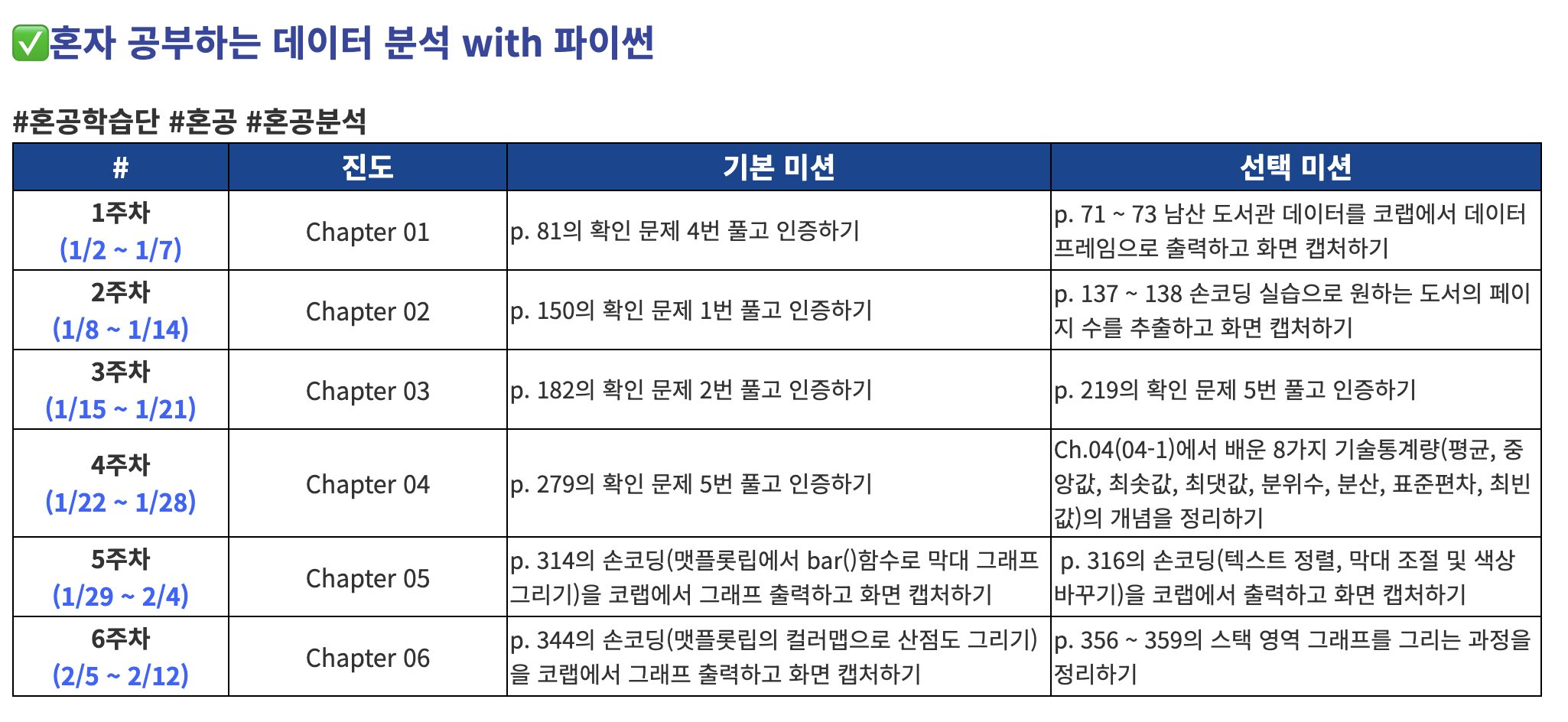
books_df.head()필요한 열만 선택하여 새로운 데이터프레임 만들기
books = books_df[['no', 'ranking', 'bookname', 'authors', 'publisher', 'publication_year', 'isbn13']]
books.head()
데이터프레임 행과 열 선택하기: loc 메서드
판다스에서 제공하는 loc 메서드를 사용하여 원하는 행과 열을 조금 더 쉽게 선택할 수 있다.
loc는 메서드이지만 대괄호를 사용하여 행의 목록과 열의 목록을 받는다.
books_df.loc[[0,1], ['bookname', 'authors']]
✔️ iloc는 무엇일까?
loc 메서드는 ‘인덱스’와 ‘열 이름’을 사용한다. 열 이름이 곧 인덱스이기 때문에 ‘열 인덱스’라고도 부른다.
iloc 메서드는 ‘인덱스의 위치’를 사용한다.
books_df의 행 인덱스는 0부터 시작하므로 인덱스와 인덱스 위치가 같다.
열의 경우 ‘no’부터 위치가 0에서 시작하여 1씩 증가한다. 따라서 앞의 코드를 iloc로 다시 쓰면 books_df.iloc[[0, 1], [2,3]]과 같다.
위 이미지에서 보면 열이 no부터 시작해서 author까지 있다. 여기서 no는 0번째 이다.
따라서 bookname은 2번째, authors 3번째 이다. iloc는 인덱스 위치를 직접 가르켜 불러온다.
리스트 대신 더욱 편리한 슬라이스 연산자(:)를 쓸 수 있다.
books_df.loc[0:1, 'bookname': 'authors']결과 값은 위에 이미지와 동일하다. 하지만 loc 메서드의 슬라이싱은 파이썬의 슬라이싱과 다르게 마지막 항목도 포함한다. 그래서 두 개의 행과 ‘bookname’, ‘authors’ 열이 모두 포함되었다.
시작과 끝을 따로 지정하지 않고 슬라이스 연산자만 사용하면 전체를 의미한다. (:)
books = books_df.loc[:, 'no':'isbn13']
books.head()
✔️ 파이썬 슬라이싱처럼 스템(step)을 지정할 수 있다. 2를 추가 하면 하나씩 건너띄면서 행을 선택한다.
books_df.loc[::2, 'no':'isbn13'].head()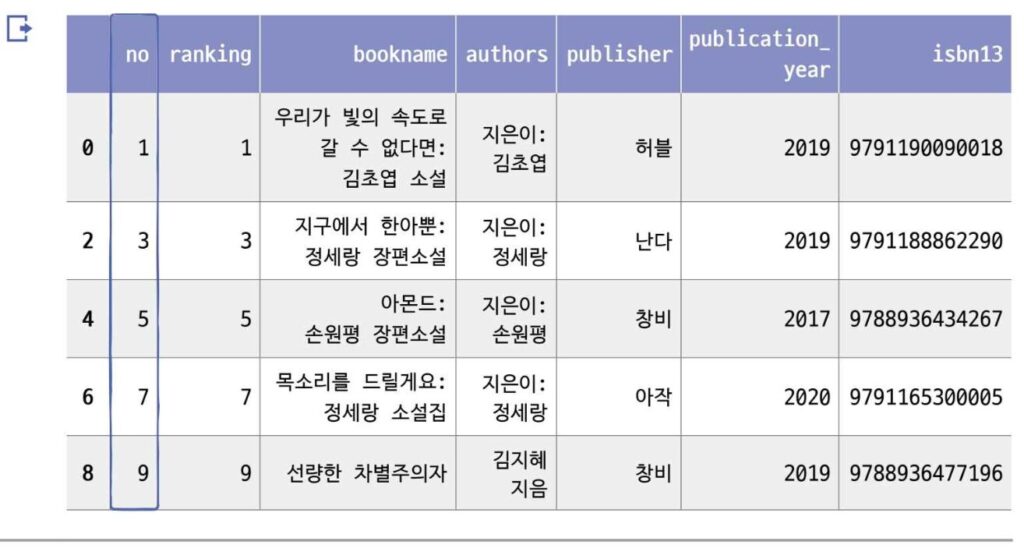
인덱스를 보면 0, 2, 4, 6, 8인 것을 확인할 수 있다.
🍒 확인문제
- 다음과 같은 데이터프레임 df가 있을 때 loc 메서드의 결과가 다른 하나는 무엇인가요?
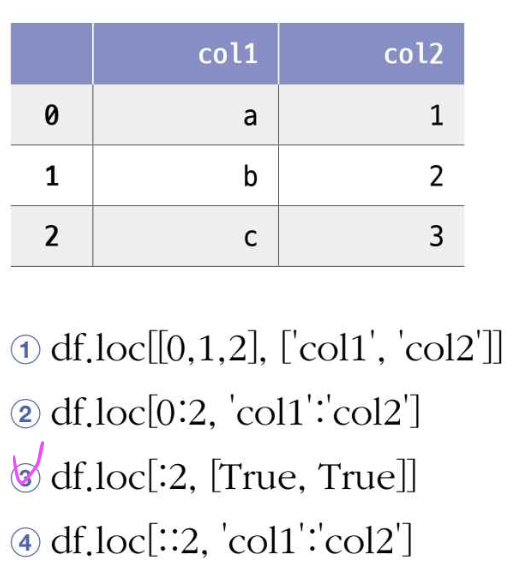
df.loc[[0,1,2], ['col1', 'col2']]는 0, 1, 2번째 행과 ‘col1’, ‘col2’라는 이름의 열을 선택한다.df.loc[0:2, 'col1':'col2']는 0부터 2번째 행까지(2 포함)와 ‘col1’부터 ‘col2’까지의 열을 선택한다. 이는 파이썬의 슬라이싱과 유사하게 작동하며, 끝 인덱스도 포함한다.df.loc[:2, [True, True]]는 0부터 2번째 행까지(2 포함)와 모든 열을 불리언 인덱싱을 사용하여 선택한다. 여기서[True, True]는 모든 열을 선택하라는 의미.df.loc[:2, 'col1':'col2']는 방법 2와 동일한 결과를 제공한다. 즉, 0부터 2번째 행까지(2 포함)와 ‘col1’부터 ‘col2’까지의 열을 선택한다.
위의 방법들 중에서 3번째 방법은 다른 세 방법과 결과가 다르다. 이유는 불리언 인덱싱을 사용하기 때문이다.
[True, True]를 사용하면 해당 열에 대한 조건을 나타내며, 여기서는 모든 열이 True로 표시되어 있어 해당 DataFrame의 모든 열을 가져온다.
다른 방법들은 모두 열의 이름을 지정하여 선택하는 반면, 3번째 방법은 열의 위치가 아닌 조건을 기반으로 열을 선택한다.
검색 결과 페이지 HTML 가져오기: requests.get() 함수
답글 남기기